AI-Powered Learning
Developing scalable tools for practicing skills with confidence and precision.
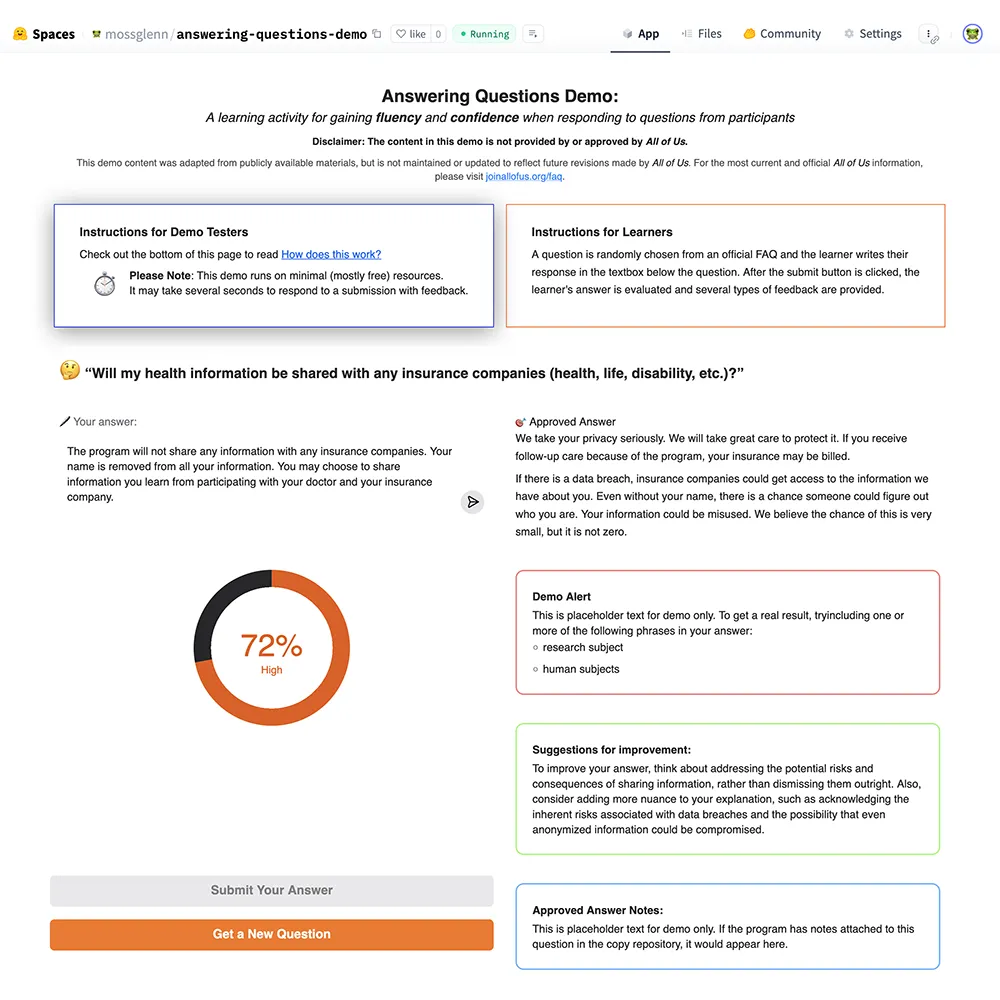

Because this project addressed a high-stakes communication skill, I began with a proof-of-concept to demonstrate that scalable, feedback-driven practice could work before investing in a full production build with a development team. The proof-of-concept was built entirely in Python using free, open-source tools: no licenses, custom infrastructure, or developer time were required at this stage. The interface was intentionally minimal (a question, a text field, and a feedback panel) to support a rapid learning loop.
In the production training environment, staff learn to respond using IRB-approved model answers. These internal answers are not public, but the All of Us website publishes public-facing FAQs based on the same source guidance. These public FAQs are accurate, written in plain language, and aligned in tone and intent with the internal training materials. For the proof-of-concept, I adapted these public FAQs as gold-standard benchmark answers for comparison. This ensured the demo respected IRB boundaries while still reflecting the communication approach expected in training.
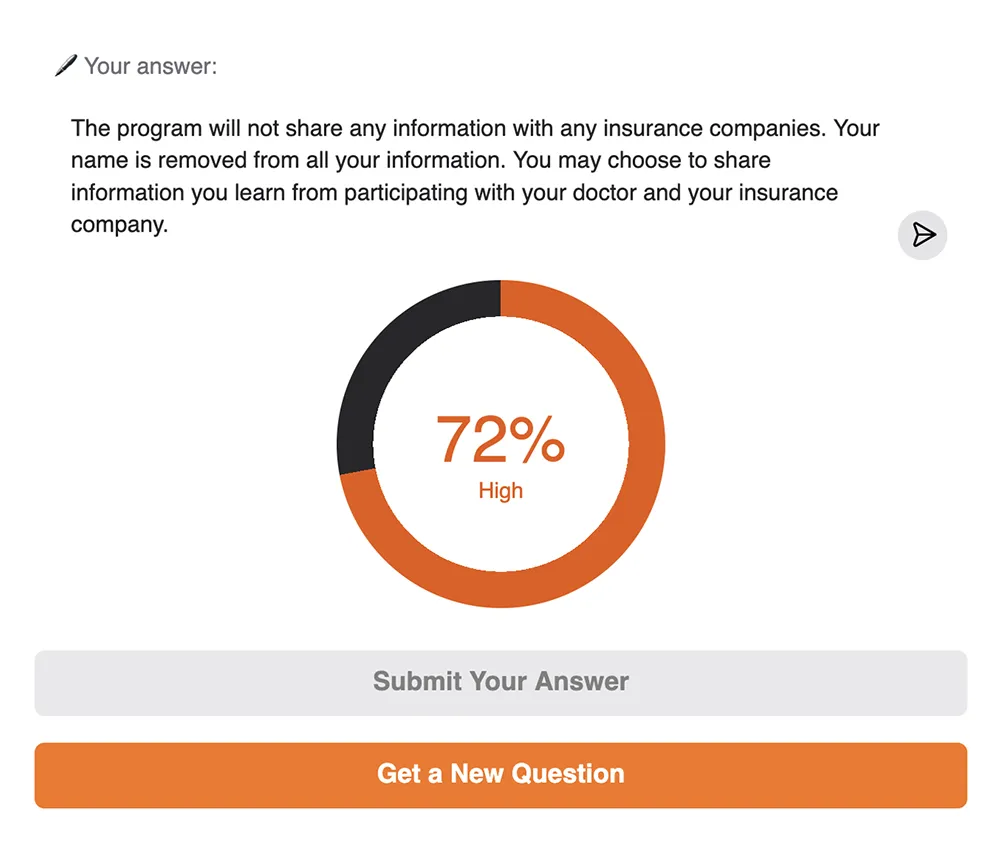
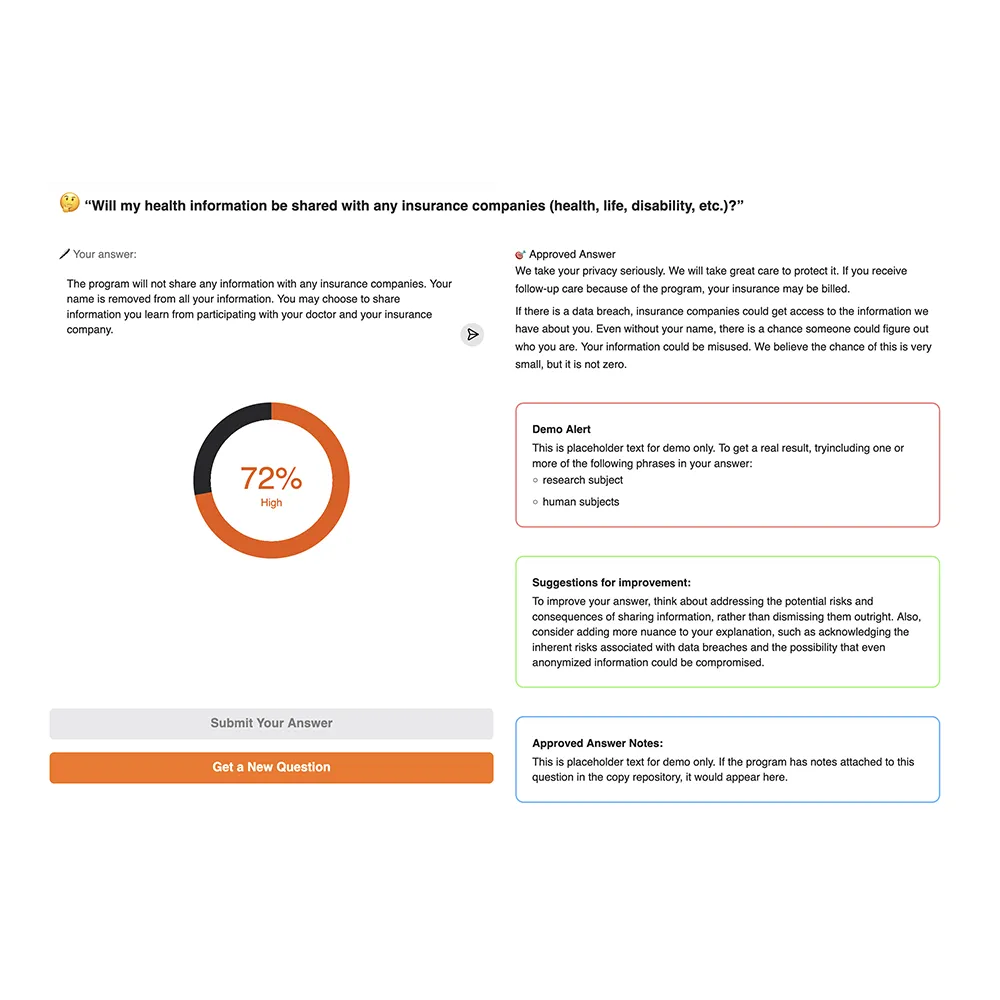
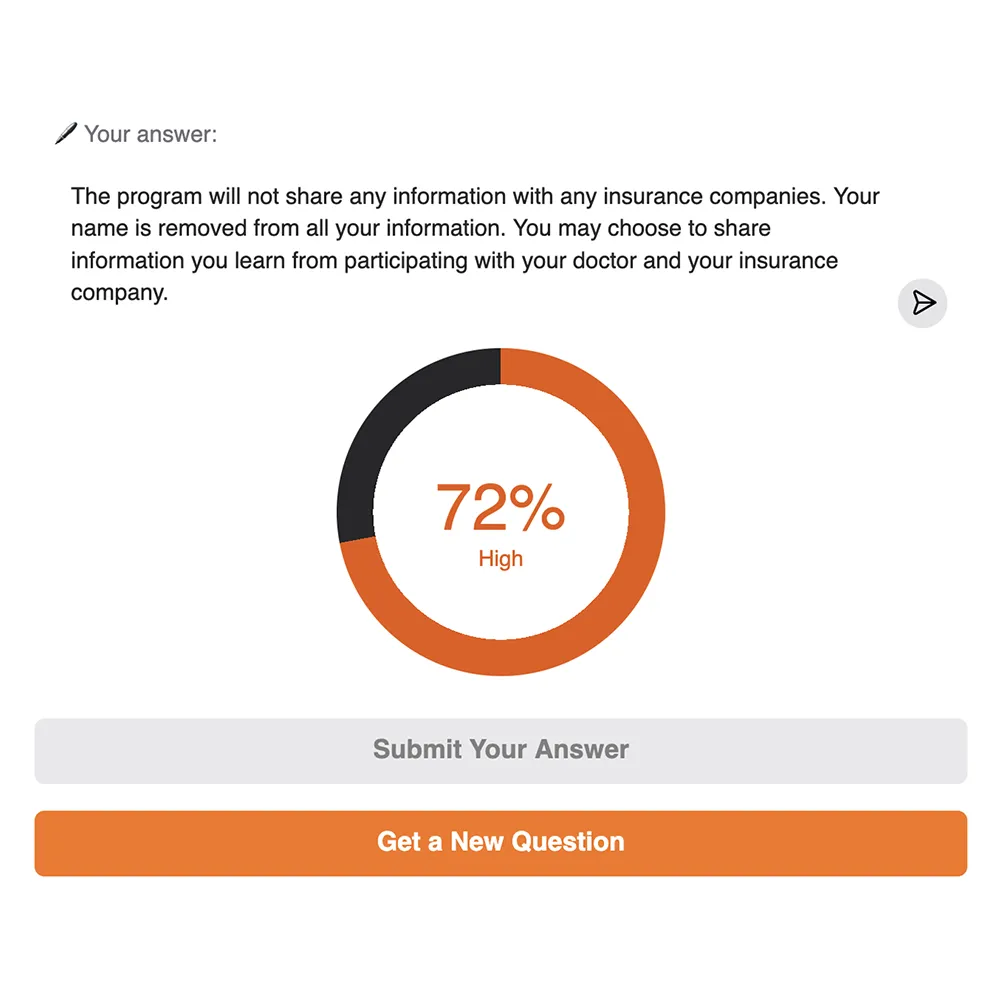
The demo ran on Hugging Face Spaces and used an open embedding model to generate semantic vector representations of (1) the learner’s written response and (2) the benchmark answer. The tool calculated cosine similarity between these vectors to assess how closely the meaning of the learner’s response aligned with the meaning of the approved content. This approach evaluates conceptual accuracy, not keyword overlap. The similarity score was then mapped to a percentage scale and a qualitative label (e.g., “Low,” “Moderate,” “High”) to make the results meaningful to the learner.
In addition to scoring similarity, the tool used a lightweight language model to compare the learner’s response to the benchmark answer and to identify differences in meaning. The tool then generated feedback text highlighting ways the learner's answer could be improved:

The training program also uses an Approved Language Framework to help staff communicate in ways that are accurate, welcoming, and aligned with the values of the research program. Some commonly used phrases can unintentionally imply incorrect assumptions, introduce ambiguity, or make community members feel excluded. To support this, the prototype included a rule-based layer that scanned the learner's responses for a representative subset of these phrases using regular-expression matching. If a flagged phrase appeared in the learner’s response, the tool provided brief, pre-written guidance explaining the reasons for avoiding the phrase and alternative wording.
I led the end-to-end design and development of this proof-of-concept. I identified the instructional problem, evaluated solution approaches, and designed the learning experience around applied practice with timely, meaningful feedback. I selected the semantic similarity approach, adapted the benchmark responses from publicly available IRB-approved FAQs, and authored the feedback prompts and scoring logic to ensure the system reinforced clarity, accuracy, and trust.
I built the prototype interface and scoring pipeline using Python and free, open-source models running on Hugging Face Spaces, allowing the solution to be tested without custom infrastructure or engineering support. I also designed the rule-based layer that checked for phrases addressed in the program’s Approved Language Framework, and drafted the explanatory guidance used to redirect learners toward clearer and more inclusive alternatives.
Because this project addressed a high-stakes communication skill, I began with a proof-of-concept to demonstrate that scalable, feedback-driven practice could work before investing in a full production build with a development team. The proof-of-concept was built entirely in Python using free, open-source tools: no licenses, custom infrastructure, or developer time were required at this stage. The interface was intentionally minimal (a question, a text field, and a feedback panel) to support a rapid learning loop.
In the production training environment, staff learn to respond using IRB-approved model answers. These internal answers are not public, but the All of Us website publishes public-facing FAQs based on the same source guidance. These public FAQs are accurate, written in plain language, and aligned in tone and intent with the internal training materials. For the proof-of-concept, I adapted these public FAQs as gold-standard benchmark answers for comparison. This ensured the demo respected IRB boundaries while still reflecting the communication approach expected in training.
The demo ran on Hugging Face Spaces and used an open embedding model to generate semantic vector representations of (1) the learner’s written response and (2) the benchmark answer. The tool calculated cosine similarity between these vectors to assess how closely the meaning of the learner’s response aligned with the meaning of the approved content. This approach evaluates conceptual accuracy, not keyword overlap. The similarity score was then mapped to a percentage scale and a qualitative label (e.g., “Low,” “Moderate,” “High”) to make the results meaningful to the learner.
In addition to scoring similarity, the tool used a lightweight language model to compare the learner’s response to the benchmark answer and to identify differences in meaning. The tool then generated feedback text highlighting ways the learner's answer could be improved:
The training program also uses an Approved Language Framework to help staff communicate in ways that are accurate, welcoming, and aligned with the values of the research program. Some commonly used phrases can unintentionally imply incorrect assumptions, introduce ambiguity, or make community members feel excluded. To support this, the prototype included a rule-based layer that scanned the learner's responses for a representative subset of these phrases using regular-expression matching. If a flagged phrase appeared in the learner’s response, the tool provided brief, pre-written guidance explaining the reasons for avoiding the phrase and alternative wording.
I led the end-to-end design and development of this proof-of-concept. I identified the instructional problem, evaluated solution approaches, and designed the learning experience around applied practice with timely, meaningful feedback. I selected the semantic similarity approach, adapted the benchmark responses from publicly available IRB-approved FAQs, and authored the feedback prompts and scoring logic to ensure the system reinforced clarity, accuracy, and trust.
I built the prototype interface and scoring pipeline using Python and free, open-source models running on Hugging Face Spaces, allowing the solution to be tested without custom infrastructure or engineering support. I also designed the rule-based layer that checked for phrases addressed in the program’s Approved Language Framework, and drafted the explanatory guidance used to redirect learners toward clearer and more inclusive alternatives.
This proof-of-concept demonstrates that meaningful, individualized feedback could be automated responsibly, without sacrificing accuracy or lowering instructional quality. It provided a validated foundation for discussions within the research program about building a production-ready tool integrated directly into the training platform.
This interactive demo lets you try the proof-of-concept tool
yourself.
Type a response to the sample question and submit it. The system will compare your answer to the approved reference
answer similar to the one used in production training. You’ll
receive a score based on semantic similarity (not keyword matching)
and suggestions for improvement. Further instructions for other
features are within the demo itself.
If the demo does not finish loading below (some browsers block embedded applications) you can open the demo on Hugging Face.